diffusers v0.15.0 の Text-to-Video Zero と ControleNet の OpenPose を併用する
前回の記事で Text-to-Video Zero で動画生成をしました。
Text-to-Video Zero は Text-to-Video だけでなく、なんと ControlNet も併用できるようです。diffusers の ControlNet は全種類使ってみましたので、凄さを知ってます!
どんな動画が出力されるのか楽しみです。
と意気揚々と記事の方を書き始めながら、
スクリプトも並行して試し始めたのですが、残念ながら以下の通りです。
OutOfMemorryError
CUDA out of memory になってしまい出力まではいけませんでした...
無料版の Google Colab では限界か...
ということで、この記事は、
「diffusers v0.15.0 の Text-to-Video Zero と ControleNet の OpenPose を併用する」
改め、
「diffusers v0.15.0 の Text-to-Video Zero と ControleNet の OpenPose を併用してみたが OutOfMemoryError になってしまい断念した」
になります。
追記
以下の記事で一応動くようになっています。
早速やってみる
コントロール画像群を準備する
Text-to-Image のときとは異なり、ポーズ情報も動画です。ドキュメント通り こちらの動画 を使わせていただきます。ダウンロードした動画は、ソースコードから扱いやすい場所に置いといてください。
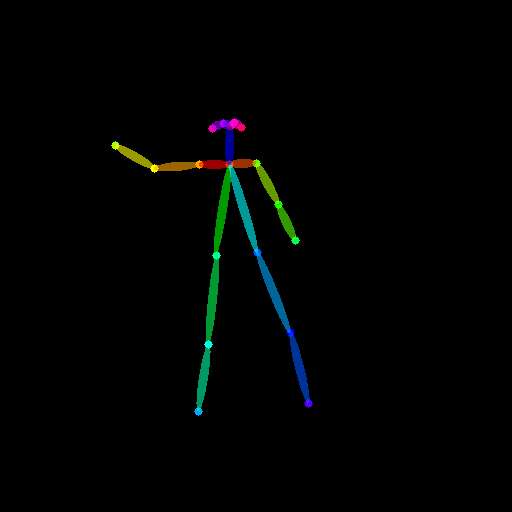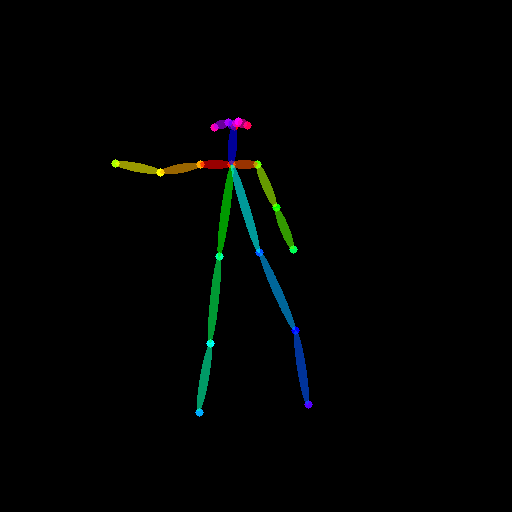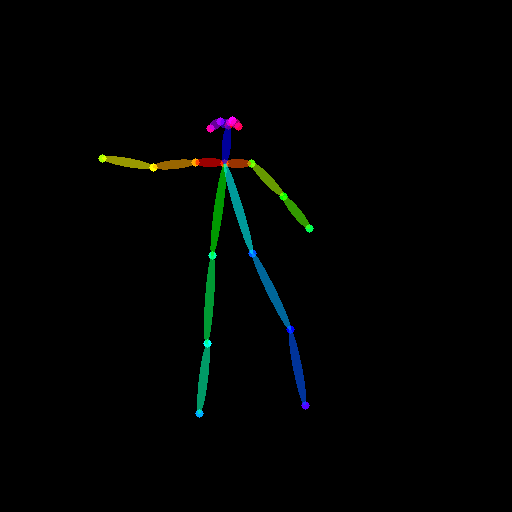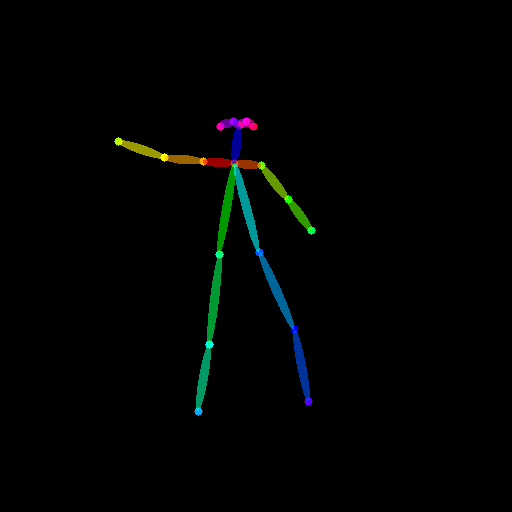
import imageio from PIL import Image # ポーズ動画のパス pose_video_path = "./dance1_corr.mp4" # ポーズ動画からポーズ画像群を取得する reader = imageio.get_reader(pose_video_path, "ffmpeg") frame_count = 8 pose_images = [Image.fromarray(reader.get_data(i)) for i in range(frame_count)]
試しに pose_images がどのように出力されているか見てみよう
for idx, pose_image in enumerate(pose_images):
pose_image.save(f"pose_image_{idx}.png")







ふむふむ。いい感じ
ControlNet 及び Pipeline の準備
import imageio
import torch
from diffusers import StableDiffusionControlNetPipeline, ControlNetModel
from diffusers.pipelines.text_to_video_synthesis.pipeline_text_to_video_zero import CrossFrameAttnProcessor
# ControlNet の準備
controlnet = ControlNetModel.from_pretrained(
# "lllyasviel/sd-controlnet-openpose",
"lllyasviel/control_v11p_sd15_openpose",
torch_dtype=torch.float16
)
# Pipeline の準備
pipe = StableDiffusionControlNetPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5",
controlnet=controlnet,
torch_dtype=torch.float16
).to("cuda")
# Set the attention processor
pipe.unet.set_attn_processor(CrossFrameAttnProcessor(batch_size=2))
pipe.controlnet.set_attn_processor(CrossFrameAttnProcessor(batch_size=2))
# fix latents for all frames
latents = torch.randn((1, 4, 64, 64), device="cuda", dtype=torch.float16).repeat(len(pose_images), 1, 1, 1)
OpenPose の ControlNetModel は新しい方にしてみました。
前回の記事では TextToVideoZeroPipeline を使用していましたが、ControlNet 併用版では 普通の ControlNetModel と 普通の StableDiffusionControlNetPipeline を使用しているようです。
ということは、想像ですが、 「Set the attention processor」 の部分が重要な役目を果たして TextToVideoZero を有効化するような動きなのでしょう。
「fix latents for all frames」
こっちも良くわからない!
こっちも良くわからない!
fix latents for all frames を Google 翻訳してみると すべてのフレームの潜在を修正 とのことなので、各フレームデータを何か直したのかもしれませんが、latents 引数の説明を見ると以下の通りなので、フレームデータを直した。というよりは、seed のように『「何か」を固定した』が正しいかもしれません。
latents ( torch.FloatTensor、オプション) — 画像生成の入力として使用される、ガウス分布からサンプリングされた、事前に生成されたノイズを含む潜在潜在。同じ世代を異なるプロンプトで微調整するために使用できます。指定されない場合、潜在テンソルは、指定された Random を使用してサンプリングすることによって生成されますgenerator。
パイプライン実行
prompt = "Darth Vader dancing in a desert"
result = pipe(prompt=[prompt] * len(pose_images), image=pose_images, latents=latents).images
imageio.mimsave("video.mp4", result, fps=4)
CUDA out of memory
_(:3 」∠)チーン...
まとめ
出力まではいけませんでしたが、ドキュメントを読み、コードを読み、やったことを記録する意味でここまできました 🙇